What Is Robots.txt
Robots.txt is a file that functions to manage search engine bots to retrieve data on a web page. Robots.txt file is used to allow or not allow search engine bots to retrieve data that is public or private, this is so that your website pages can be managed properly. Every web page must have several web pages that do not need to be indexed by search engines, for example, an admin page, it is impossible for an admin page to be displayed in Google's SERP, it will harm your site. The pages that are displayed in the search engine SERPs should be web pages that are intended for the public. Therefore this file is very helpful in managing website pages.
But in its implementation, sometimes you get confused in implementing what to do in writing robots.txt, with this tool you can see other sites how they manage their entire website pages, you can follow them by seeing what is in the robots.txt, but adapted to your website. Also with this tool, you can monitor your robots.txt file regularly to keep it properly maintained and see what web pages are allowed to be crawled by bots.
Structure in Robots.txt
To know more, we also need to know what the contents of the robots txt code are, the sample content of the code from the file looks something like this:
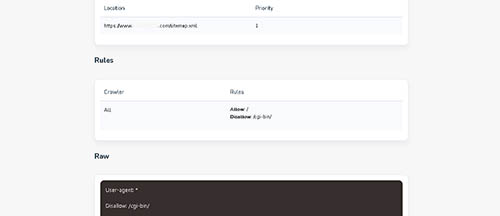
As we can see there are 4 elements used, namely User-agent, Allow, Disallow and Sitemap.
1. User-agent
User-agent is the name of the search engine bots that are allowed to crawl your website, the wildcard sign indicates that all bots can crawl web pages. But you can also use this specifically, for example: User-agent: Googlebot or User-agent: *
2. Allow
Then next is Allow, Allow itself is a command for search bots to view the contents of web pages in certain urls. The slash sign itself is telling that all web pages can be indexed into search engines.
3. Disallow
Disallow is the opposite of Allow, which means a ban on search bots crawling to do indexing. Disallow is usually used to determine which pages we don't want indexed by search engines, for example admin pages, categories, tags, search etc. Example of its use: Disallow: /admin Disallow: /category
4. Sitemap
Sitemap is a command code to determine the address of your xml sitemap document. Google itself says using this is optional, you can use it or not. An example of its use: Sitemap: https://example.com/sitemap.xml There is one other element contained in this file, namely crawl delay.
5. Crawl Delay
Crawl delay itself is that we as site owners set the speed for search engine bots when crawling. And Crawl delay is optional, it doesn't matter if you don't use it.
Benefits of Using Robots.txt
The use of robots.txt is very important for blogs, sites and e-commerce that have many pages. For sites that do not have so many pages, actually not using this is fine, but we recommend using it, why? At least there are several benefits that can be felt, including this can prevent the server from experiencing overload Prevent duplicate content on site pages Prevent strict or private site pages from being indexed in the SERP.
Check Your Robots.txt File Regularly
Regularly checking Robots txt will make your site healthier, maybe you will add some new information to your robots txt, and when you are making changes to your robots txt file, you also need to see if it is appropriate or not. Errors in Robots txt information will result in bots from search engines not crawling your web pages, this is usually caused by incorrect information in your robots txt file.
How Do I Use This Robots txt Tester & Validator Tool?
Using Genelify Robots Txt Tester & Validator Tool is quite easy, you only need to enter the URL of your web page and our system will analyze your robots.txt file automatically and the results will be displayed to you. This tool is completely free with no limitations, you can use this tool whenever you need.